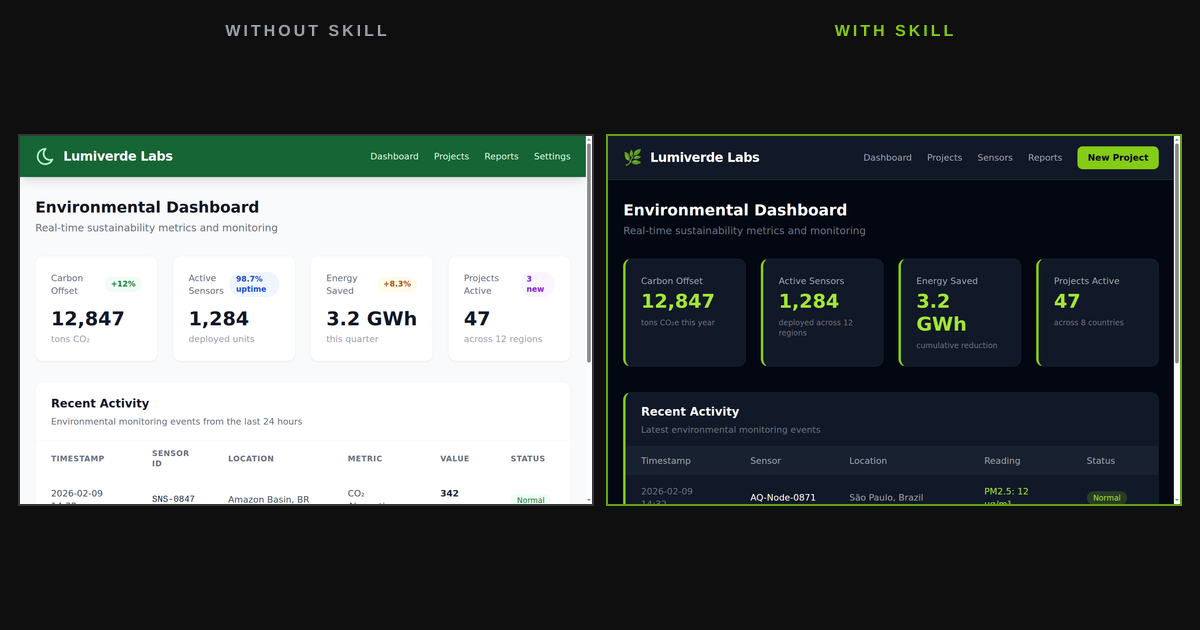
claude-code agentregistry skills
AgentRegistry + Claude Code: A Developer's Guide to Team-Wide Skill Distribution
A hands-on walkthrough of authoring, publishing, and consuming Claude Code skills with AgentRegistry — the open-source registry that treats AI skills as first-class distributable artifacts.
Read more


