langsmith observability opentelemetry
Implementing Compliant AI Tracing with LangSmith
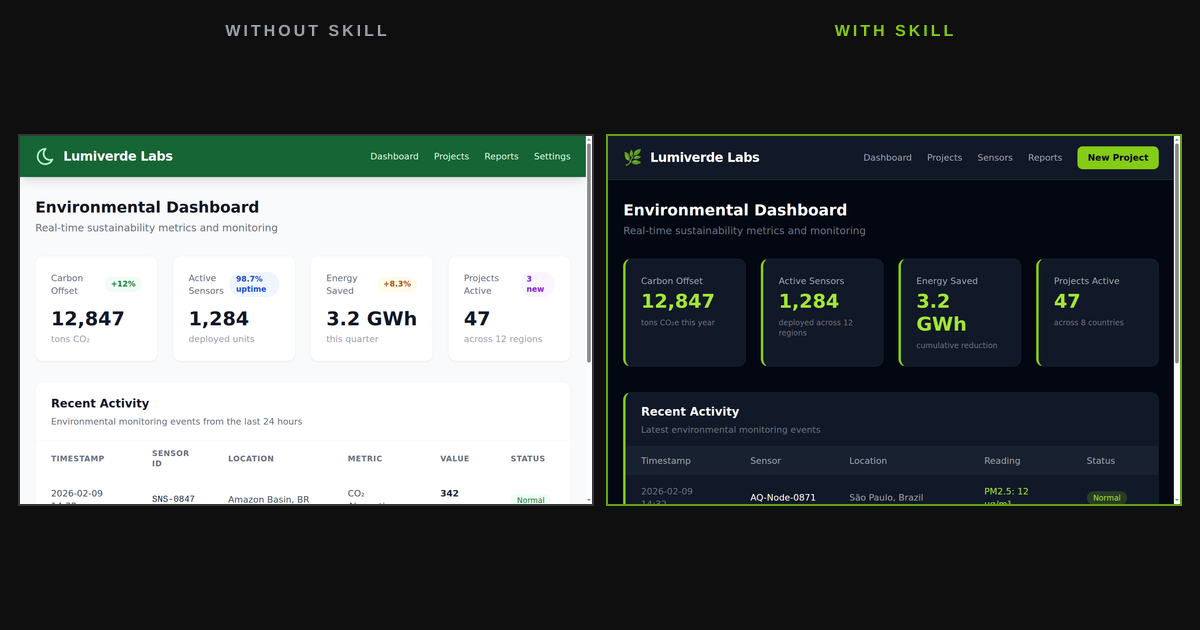
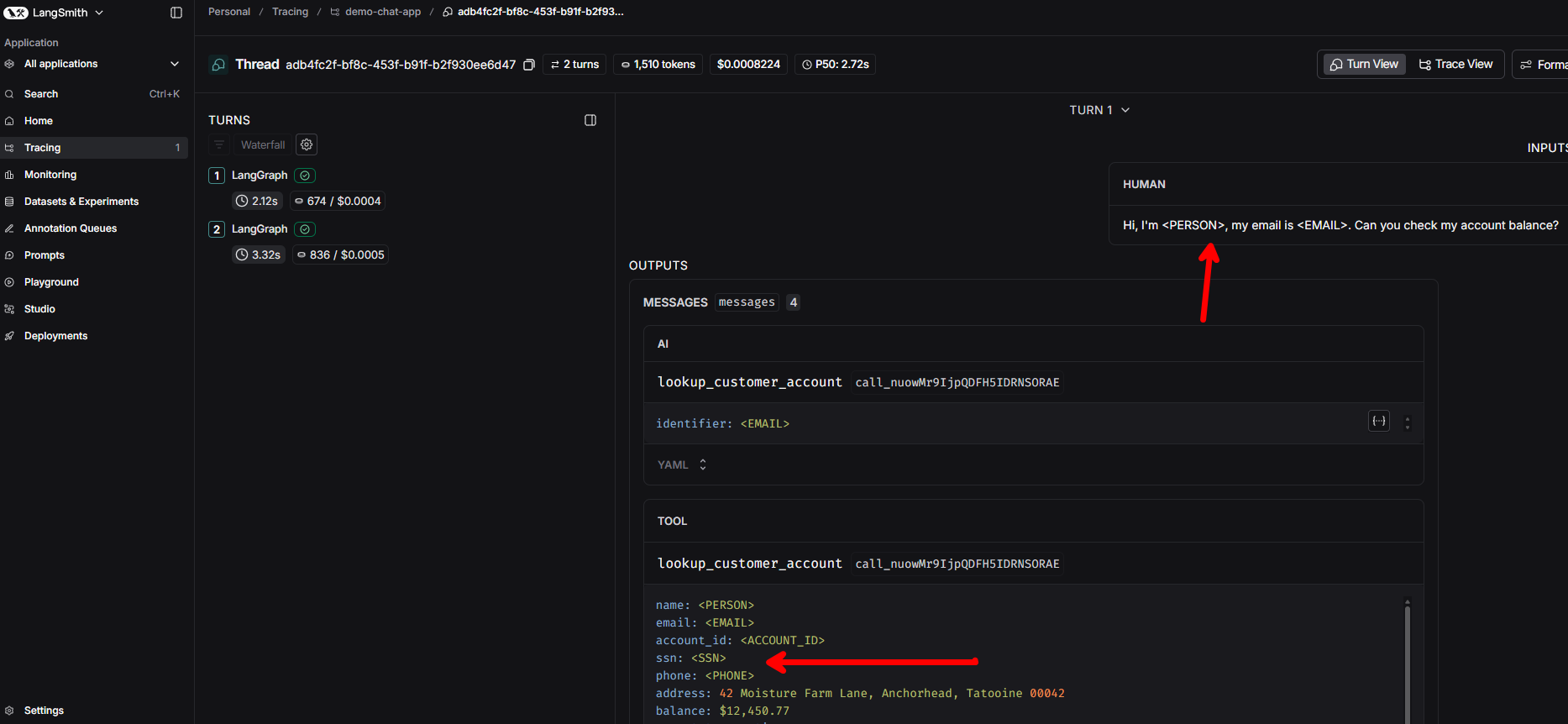
How to build observable AI systems that support frameworks like NIST AI RMF using LangSmith tracing with client-side PII redaction, streaming instrumentation, and thread linking — plus a production architecture using the OpenTelemetry Collector.
Read more